
API configuration
Set up an experiment with the Velvet API
Set up experiments to test models, settings, and metrics. Replay experiments against historical logs to understand the performance of each variant.
The API is useful for more sophisticated use cases. Refer to our UI configuration docs for standard use cases.
How it works
- Define a dataset using a SQL query or CSV upload
- Configure the experiment in JSON
- Run the experiment with the API
- View results in your database or in the Velvet UI
(1) Create your dataset
Create a dataset containing the input data you want to test. Use SQL queries to fetch data from your database, or upload a CSV file.
Here's an example SQL query to select 5 random system prompts, user prompts, and responses from your logs database.
SELECT
request->'body'->'messages'->0->>'content' AS system_prompt,
request->'body'->'messages'->1->>'content' AS user_prompt,
response->'body'->'choices'->0->'message'->>'content' AS response,
(response->'body'->'choices'->0->'message'->>'content')::json->>'search_type' AS search_type_value
FROM
llm_logs
WHERE
response->'body'->'choices'->0->'message'->>'content' LIKE '%search_type%'
ORDER BY
RANDOM()
LIMIT 5;
Here's the same dataset, in CSV format (Google Sheet version here).
| System prompt | User prompt | Response | search_type_value |
|---|---|---|---|
| Given a user's query, your job is to determine whether they are searching for 'companies' or 'people'. Respond with JSON in the format of {"search_type": "companies"} or {"search_type": "people"}. Make a best guess and always return one of those two. | Ice cream shops in nyc | { "search_type": "companies" } | companies |
| Given a user's query, your job is to determine whether they are searching for 'companies' or 'people'. Respond with JSON in the format of {"search_type": "companies"} or {"search_type": "people"}. Make a best guess and always return one of those two. | AI founders | { "search_type": "people" } | people |
| Given a user's query, your job is to determine whether they are searching for 'companies' or 'people'. Respond with JSON in the format of {"search_type": "companies"} or {"search_type": "people"}. Make a best guess and always return one of those two. | VC-funded startups | { "search_type": "companies" } | companies |
| Given a user's query, your job is to determine whether they are searching for 'companies' or 'people'. Respond with JSON in the format of {"search_type": "companies"} or {"search_type": "people"}. Make a best guess and always return one of those two. | Biggest startups in new york city | {"search_type": "companies"} | companies |
| Given a user's query, your job is to determine whether they are searching for 'companies' or 'people'. Respond with JSON in the format of {"search_type": "companies"} or {"search_type": "people"}. Make a best guess and always return one of those two. | AI founders in sf | {"search_type": "people"} | people |
Once you've created and saved your dataset using either SQL or CSV, you can reference it in your experiment configuration.
(2) Configure your experiment with JSON
Provide a JSON configuration of the experiment. Note, you can also set up an experiment via the UI, but the API is best for more advanced or custom use cases.
Define prompts to test
Use double curly braces as placeholders for variables: {{variable_name}}
"prompts": [
[
{
"role": "system",
"content": "{{system_prompt}}"
},
{
"role": "user",
"content": "{{user_prompt}}"
}
]
]
Define models to test
Specify the LLM providers you want to test and their model configurations.
Note, OpenAI supports the following model formats:
openai:<model name>- uses a specific model name (mapped automatically to chat or completion endpoint)openai:embeddings:<model name>- uses any model name against the/v1/embeddingsendpoint
"providers": [
{
"id": "openai:gpt-3.5-turbo-0125",
"config": {
"max_tokens": 1024,
"temperature": 0.5
}
},
{
"id": "openai:gpt-4o-mini",
"config": {
"temperature": 0.5,
"max_tokens": 1024,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0
}
}
]
Define inputs to evaluate
The var question below contains example inputs from a logs dataset. Each variant of the experiment will run on top of each input you include.
Set metrics, each will run automatically and output a score. Tests should contain core use cases and potential failures for your prompts.
"tests": [
{
"assert": [
{
"type": "latency",
"threshold": 1500
},
{
"type": "model-graded-closedqa",
"value": "Provides a clear, concise answer"
}
],
"vars": {
"question": [
"What are large language models (LLMs)?",
"Can you tell me a joke?",
"How can I write my own compiler?",
"What's the meaning of life?",
"Can you write a query that joins two tables?",
"Can you recommend a good book?",
"What's your favorite food?",
"What are your hobbies and how did you get into them?",
"What's your go-to board game?",
"What does your future hold?"
]
}
}
]
Velvet also supports importing tests from a Google Sheet url. See the Google Sheet link below for an example.
"tests": "https://docs.google.com/spreadsheets/d/1KUZqbEZvOcglaNC4JGte8ICkKpp-1W0k07L7gi5j2sQ/edit?usp=sharing"
See Deterministic Evaluations and LLM Based Evaluations for a list of supported evaluation metrics. Velvet supports a variety of evaluation assertions out of the box.
Complete JSON example
Here's an example experiment configuration on JSON outputs that evaluates the quality of a prompt between gpt-3-turbo and gpt-4o-mini with logs and evaluation metrics imported from a Google Sheet csv.
{
"name": "Google Sheet Experiment",
"description": "Testing the performance of two OpenAI models on JSON outputs.",
"prompts": [
[
{
"role": "system",
"content": "{{system_prompt}}"
},
{
"role": "user",
"content": "{{user_prompt}}"
}
]
],
"providers": [
{
"id": "openai:gpt-3.5-turbo-0125",
"config": {
"response_format": {
"type": "json_object"
}
}
},
{
"id": "openai:gpt-4o-mini",
"config": {
"response_format": {
"type": "json_object"
}
}
}
],
"tests": "https://docs.google.com/spreadsheets/d/1KUZqbEZvOcglaNC4JGte8ICkKpp-1W0k07L7gi5j2sQ/edit?usp=sharing"
}
An experiment will run each prompt through a series of variable inputs and check if they meet the evaluation assertions.
(3) Run experiment
To run an experiment, make an API call to the below endpoint.
POST https://www.usevelvet.com/api/experiments
Required headers:
- Content-Type: application/json
- Authorization: Bearer [Your-Velvet-API-Token]
- velvet-user: [Your-User-ID]
Body:
- [Your JSON experiment configuration] (see example configuration above)
Complete request example
See the example curl request with the required headers to run a new experiment with the example config from above.
Fill in your and to try. Find these under the Experiment tab of your Velvet workspace ("API setup").
curl --request POST \
--url https://www.usevelvet.com/api/experiments \
--header 'Content-Type: application/json' \
--header 'authorization: sk_velvet_prod_<api-key>' \
--header 'velvet-user: user_<user-id>' \
--data '{
"name": "Google Sheet Experiment",
"description": "Testing the performance of two OpenAI models on JSON outputs.",
"prompts":[
[
{
"role": "system",
"content": "{{system_prompt}}"
},
{
"role": "user",
"content": "{{user_prompt}}"
}
]
],
"providers":[
{
"id":"openai:gpt-3.5-turbo-0125",
"config":{
"response_format": { "type": "json_object" }
}
},
{
"id":"openai:gpt-4o-mini",
"config":{
"response_format": { "type": "json_object" }
}
}
],
"tests": "https://docs.google.com/spreadsheets/d/1KUZqbEZvOcglaNC4JGte8ICkKpp-1W0k07L7gi5j2sQ/edit?usp=sharing"
}'
(4) View results of your experiment
Review results in your database
You can view the raw data of the experiment directly in your own database. This allows you to build your own analytics dashboards with SQL, and analyze the experiments in more detail.
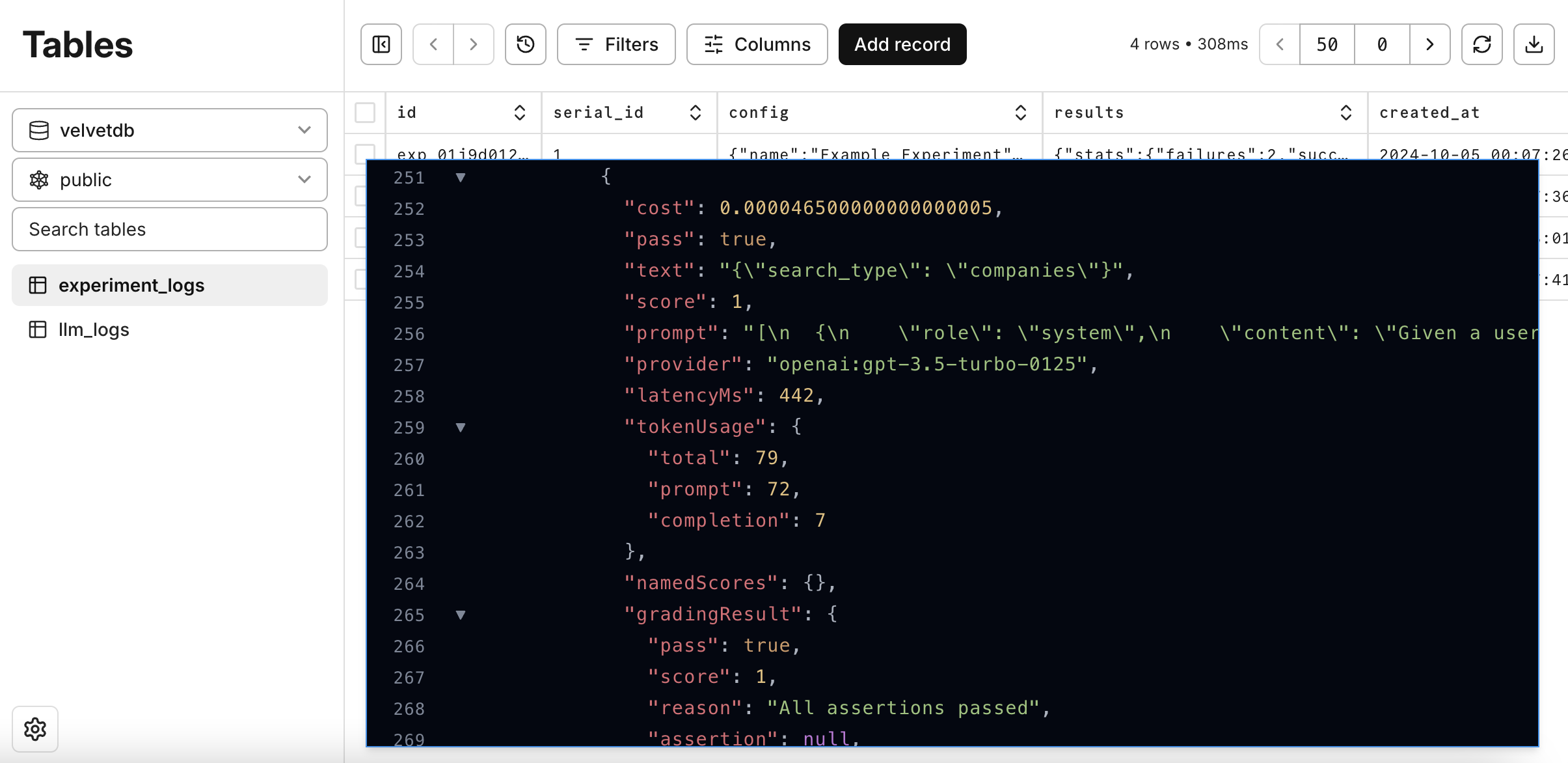
Review results in the UI
You can also view the results in the ‘Experiments’ tab of your Velvet workspace. This makes it easier for non-technical stakeholders to analyze outcomes.
See a list of each experiment you’ve run, with a summary of configuration and pass rate.
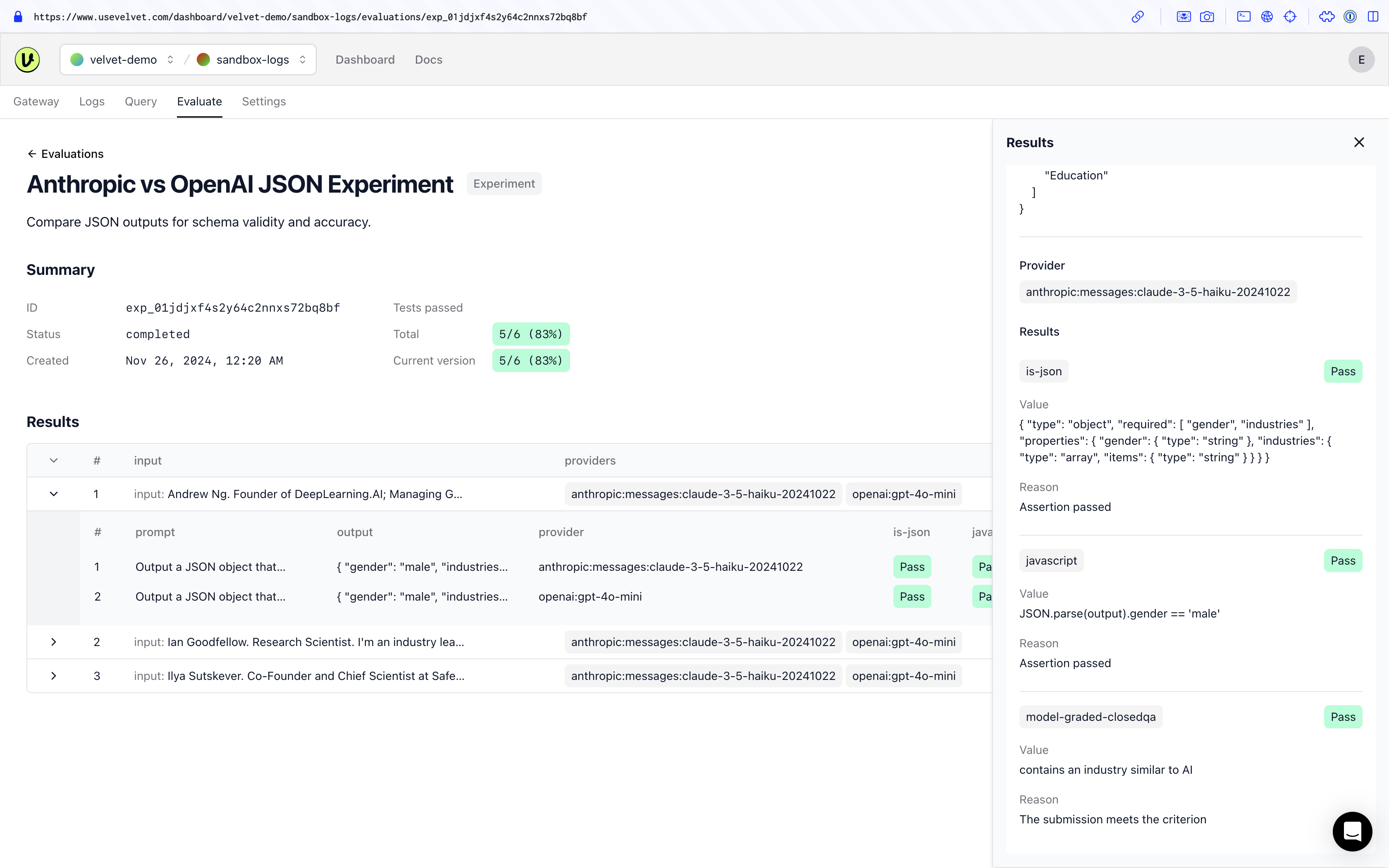
Head over to our configuration reference docs for additional evaluation examples the API supports.
Watch a video overview
Email team@usevelvet.com with any questions.
Updated 2 months ago