
Monitoring
Continuously test models, settings, and metrics in production
Sample logs from your LLM-powered features in production, and get weekly alerts on performance.
How it works
- Select the dataset and frequency of test
- Configure evaluation
- Review results and get weekly updates
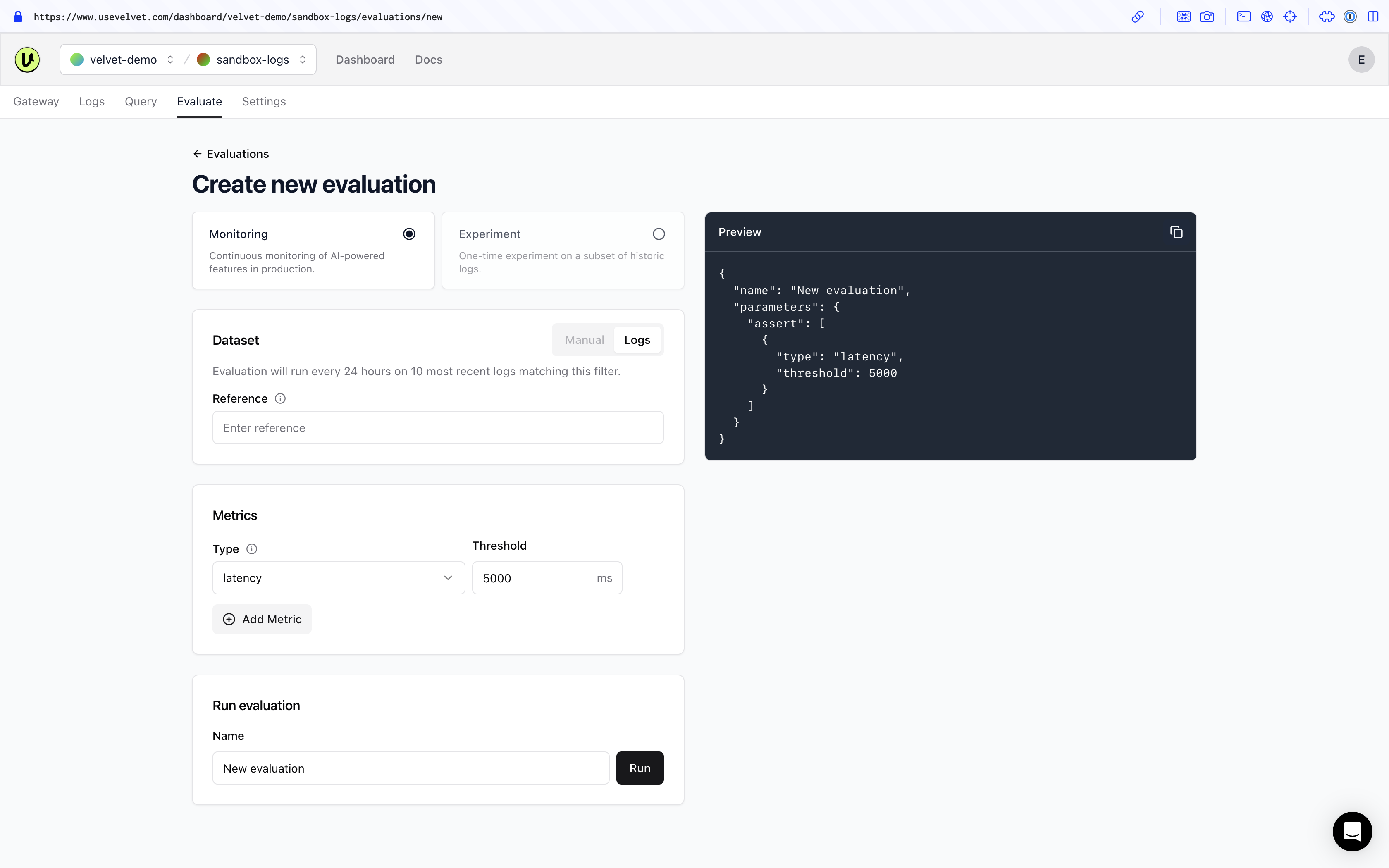
(1) Create a new test
Navigate to the evaluations tab inside your workspace to get started.
- Click the button for 'new evaluation' and select 'monitoring'.
- Select the dataset (logs) you want to run tests against.
- Select which model you want to test. The default is pulled from the selected log.
- Select the metric you want to test. The default is pulled from the selected log.
The gateway supports these providers and models out-of-the-box, including all their versions, like gpt-4o-2024-11-20 and claude-3-5-sonnet-20241022. We can support additional providers and models on our paid plans.
| Provider support | Model |
|---|---|
| OpenAI | o1-preview o1-mini gpt-4o gpt-4o-mini gpt-4-turbo gpt-4 gpt-3.5-turbo more |
| Anthropic | claude-3-5-sonnet claude-3-5-haiku claude-3-opus claude-3-haiku claude-3-sonnet more |
| Other | Email [email protected] for additional provider support |
You can leverage these metrics when configuring an evaluation from the Velvet app. For additional flexibility, see our API configuration docs.
| Metric support | Description |
|---|---|
| latency | latency is below a threshold (milliseconds) |
| cost | Inference cost is below a threshold |
| llm-rubric | LLM output matches a given rubric, using a Language Model to grade output |
| equals | output matches exactly |
| is-json | output is valid json (optional json schema validation) |
| perplexity | Perplexity is below a threshold |
| Similar | Embeddings and cosine similarity are above a threshold |
| answer-relevance | Ensure that LLM output is related to original query |
| context-faithfulness | Ensure that LLM output uses the context |
| context-recall | Ensure that ground truth appears in context |
| context-relevance | Ensure that context is relevant to original query |
| factuality | LLM output adheres to the given facts, using Factuality method from OpenAI eval |
| model-graded-close-qa | LLM output adheres to given criteria, using Closed QA method from OpenAI eval |
| select-best | Compare multiple outputs for a test case and pick the best one |
| contains | output contains substring |
| contains-all | output contains all list of substrings |
| contains-any | output contains any of the listed substrings |
| contain-json | output contains valid json (optional json schema validation) |
| icontains | output contains substring, case insensitive |
| icontains-all | output contains all list of substrings, case insensitive |
| icontains-any | output contains any of the listed substrings, case insensitive |
| javascript | provided Javascript function validates the output |
| levenshtein | Levenshtein distance is below a threshold |
| regex | output matches regex |
| other | Email [email protected] for additional metric support |
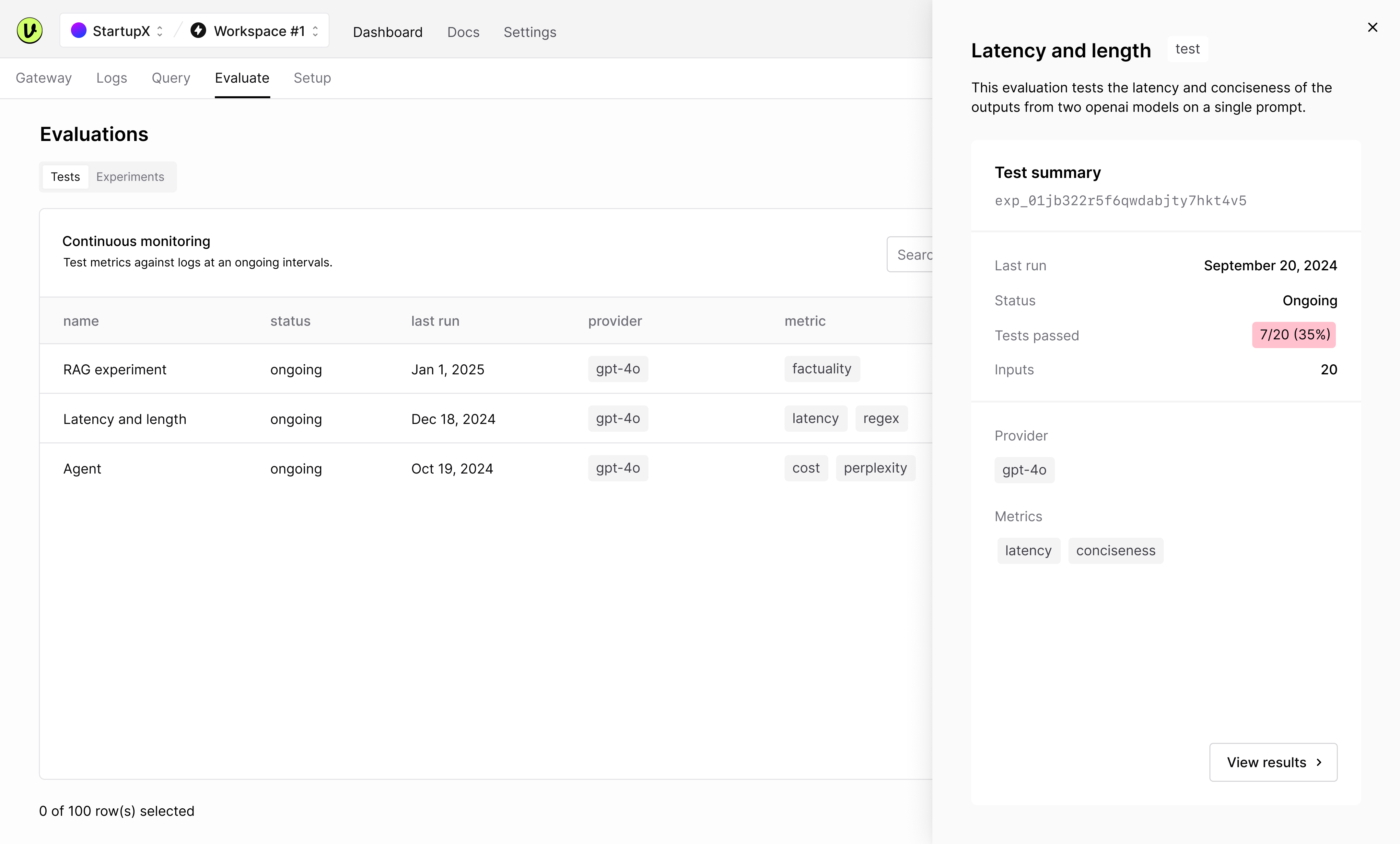
(2) Review ongoing test results
Navigate to the tests tab once configured. Tap into the evaluation you want to review.
Tests will run continuously at the defined interval. You'll get a weekly email summary of ongoing tests.
Watch a video overview
Email [email protected] with any questions.
Updated 2 months ago