
RAG evaluations
Practical evaluations for improving RAG performance
Retrieval-augmented generation (RAG) is a technique for enhancing LLM prompts by pointing at particular datasets. This evaluation example is meant to protect against low-quality retrievals, hallucinations, and other risks associated with relying on arbitrary web documents. As a result, we'll verify the correctness of the LLM output.
Issues with RAG
- Low-Quality Retrievals: The effectiveness of RAG depends on the quality of retrieved context documents. The model's ability to produce accurate responses is limited by access to relevant passages. For example, a legal advice AI that retrieves outdated case law is likely to output inaccurate advice.
- Hallucination and Fabrication: RAG models frequently generate plausible but incorrect statements due to over-reliance on language model priors. Consider a travel planning AI that fabricates details about non-existent tourist attractions.
- Safety and Control Risks: Conditioning text generation on arbitrary web documents means RAG models can inadvertently spread harmful content. For example, a health information AI might accidentally source content from unreliable websites, promoting dangerous health myths.
Evaluate RAG
- Evaluate Document Retrieval: Test metrics such as relevance to ensure the best documents are being retrieved from the vector store. Continuously monitor and improve the quality of the RAG process.
- Compare LLM Output: Thoroughly test prompts and models to assess the correctness and relevance of the LLM output. Compare outputs across different scenarios.
- End-to-End Quality Evaluation: Test the entire RAG pipeline from document retrieval to LLM output. Ensure overall performance and quality.
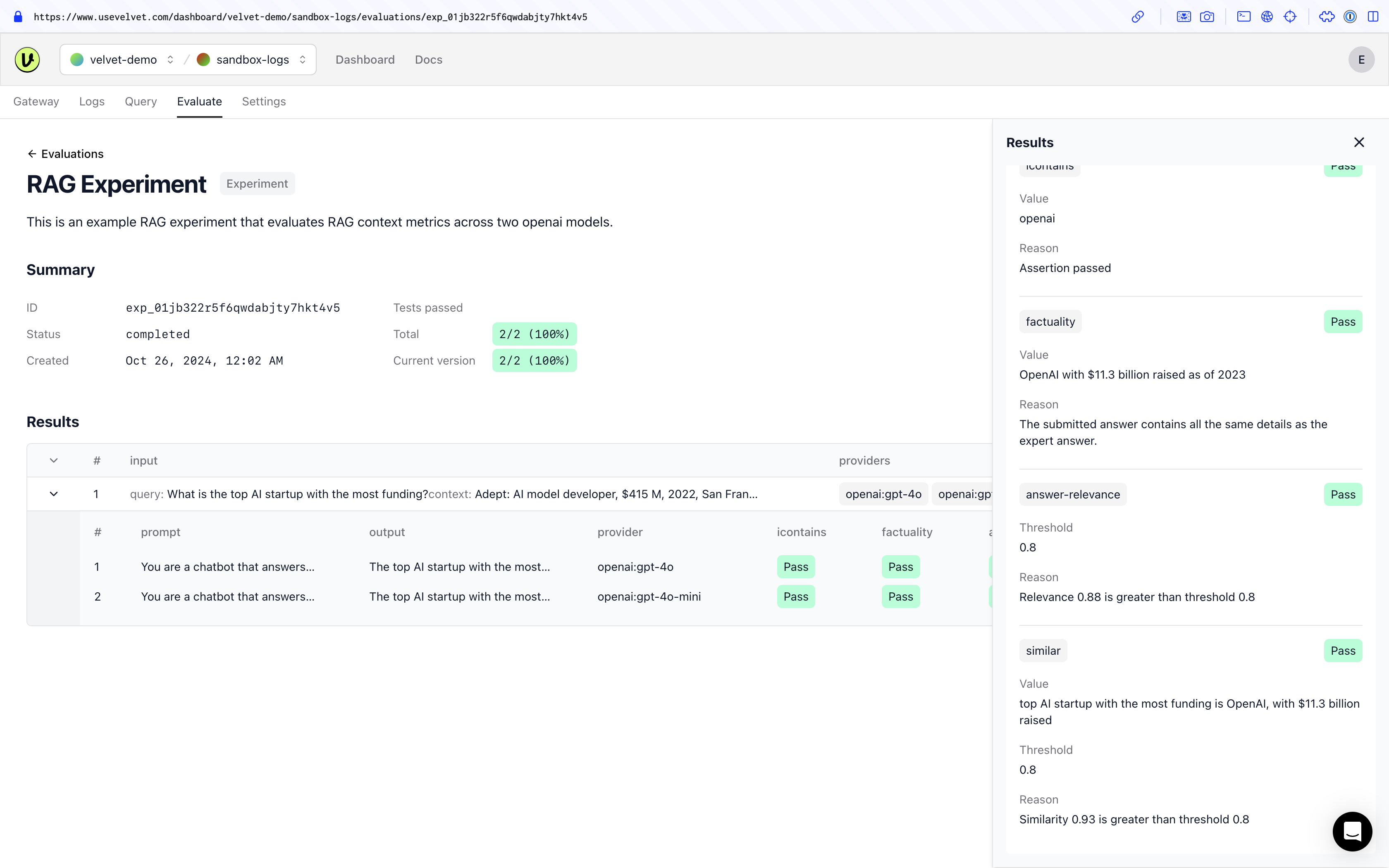
See this RAG experiment example in the Velvet demo space.
Example
Evaluating Document Retrieval
Document retrieval is the first step in a RAG pipeline. It is essential to evaluate this step in isolation to ensure the best documents are fetched.
Here’s an example of how to call an API to test document retrieval:
{
"providers": [
{
"id": "https",
"config": {
"url": "https://example-document-retrieval.com/query",
"method": "POST",
"headers": {
"Content-Type": "application/json"
},
"body": {
"query": "{{query}}"
}
}
}
]
}
Document Retrieval Configuration
Set up an evaluation that runs live document retrieval against the vector database. Create a config with test cases to ensure expected output appear in the document results.
Here’s an example config of a document retrieval evaluation:
{
"name": "RAG Document Retrieval Test",
"prompts": [
"{{ query }}"
],
"providers": [
{
"id": "https",
"config": {
"url": "https://example-document-retrieval.com/query",
"method": "POST",
"headers": {
"Content-Type": "application/json"
},
"body": {
"query": "{{query}}"
}
}
}
],
"tests": [
{
"vars": {
"query": "Top AI startups with most funding"
},
"assert": [
{
"type": "contains-all",
"value": [
"https://www.crunchbase.com/organization/anthropic",
"https://www.crunchbase.com/organization/openai",
"https://www.crunchbase.com/organization/databricks"
]
}
]
},
{
"vars": {
"query": "AI startup founders with a dog"
},
"assert": [
{
"type": "contains-all",
"value": [
"https://www.linkedin.com/in/philippekahn",
"https://www.linkedin.com/in/juliannaelamb"
]
}
]
}
]
}
Evaluating LLM Output and End-to-End Quality
Once confident in the retrieval step, evaluate the LLM's performance. Set up a prompt and test cases to check the LLM output for correctness and relevance.
Example prompt:
You are a chatbot that answers questions.
Respond to this query in one statement: {{query}}
Here is some context that you can use to write your response: {{context}}
End-to-End Configuration
Here’s an example RAG experiment configuration:
{
"name": "RAG Experiment",
"description": "This is an example RAG experiment that evaluates RAG context metrics across two openai models.",
"prompts": [
"You are a chatbot that answers questions.\\nRespond to this query in one statement: {{query}}\\nHere is some context that you can use to write your response: {{context}}"
],
"providers": [
{ "id": "openai:gpt-4o" },
{ "id": "openai:gpt-4o-mini" }
],
"tests": [
{
"vars": {
"query": "What is the top AI startup with the most funding?",
"context": "Adept: AI model developer, $415 M, 2022, San Francisco, California, United States; Anduril Industries: Defense software and hardware, $2.8 B, 2017, Costa Mesa, California, United States; Anthropic: AI model developer, $7.7 B, 2020, San Francisco, California, United States; Databricks: Data storage and analytics, $4 B, 2013, San Francisco, California, United States; Glean: Enterprise search engine, $360 M, 2019, Palo Alto, California, United States; Hugging Face: Library for AI models and datasets, $395 M, 2016, New York, New York, United States; Insitro: Drug discovery and development, $643 M, 2018, San Francisco, California, United States; Notion: Productivity software, $330 M, 2013, San Francisco, California, United States; OpenAI: AI model developer, $11.3 B, 2015, San Francisco, California, United States; Scale AI: Data labeling and software, $600 M, 2016, San Francisco, California, United States."
},
"assert": [
{
"type": "icontains",
"value": "openai"
},
{
"type": "factuality",
"value": "OpenAI with $11.3 billion raised as of 2023"
},
{
"type": "answer-relevance",
"threshold": 0.8
},
{
"type": "similar",
"value": "top AI startup with the most funding is OpenAI, with $11.3 billion raised",
"threshold": 0.8
}
]
}
]
}
Summary
Retrieval-augmented generation (RAG) is a powerful tool for enhancing LLM prompts with external data, but can lead to issues like low-quality retrievals and hallucinations. Run RAG evaluations to get a precise comparison of LLM outputs and thorough end-to-end quality assessments.
Updated 2 months ago