
UI configuration
Set up a standard experiment in the Velvet app
Set up experiments to test models, settings, and metrics. Replay experiments against historical logs to understand the performance of each variant.
UI-based configuration includes common models, provider configuration, and metrics. For more unique or complex use cases, refer to our API-based configuration docs.
How it works
- Select log for experiment
- Configure evaluation
- Review experiment results
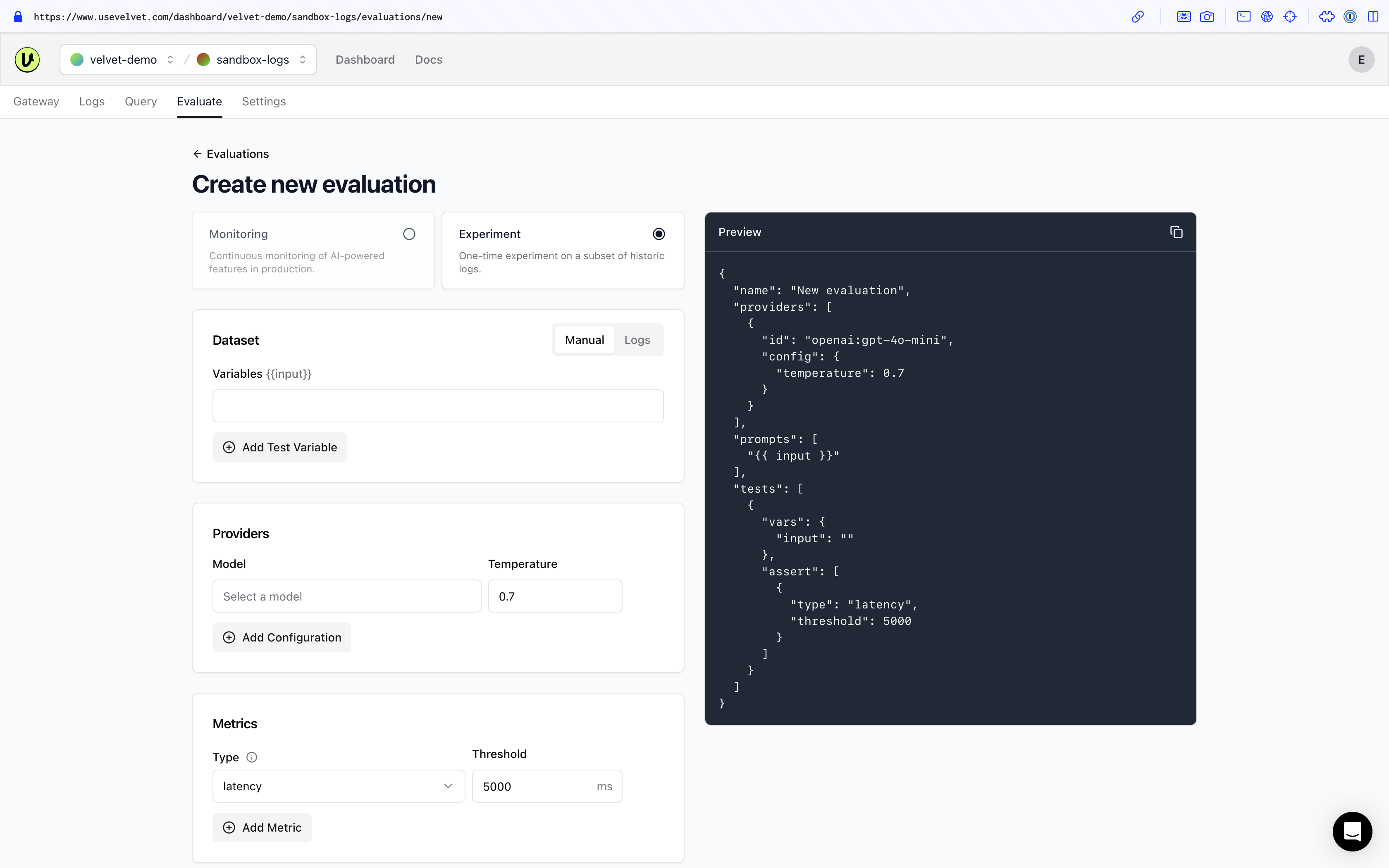
(1) Create a new experiment
Navigate to the evaluations tab inside your workspace to get started.
- Click the button for 'new evaluation' and select 'experiment'.
- Select the dataset (logs) you want to run tests against.
- Select which model(s) you want to test.
- Define the metric(s) you want to test.
The gateway supports these providers and models out-of-the-box. We can support additional providers and models on our paid plans.
| Provider support | Model |
|---|---|
| OpenAI | gpt-4o-mini gpt-4o gpt-4-turbo gpt-4 gpt-3.5-turbo more |
| Anthropic | claude-3-5-sonnet-20241022 claude-3-5-sonnet-20240620 claude-3-5-haiku-20241022 claude-3-haiku-20240307 claude-3-sonnet-20240229 claude-3-opus-20240229 |
| Other | Email [email protected] for additional provider support |
You can leverage these metrics when configuring an evaluation from the Velvet app. For additional flexibility, see our API configuration docs.
| Metric support | Description |
|---|---|
| latency | latency is below a threshold (milliseconds) |
| cost | Inference cost is below a threshold |
| llm-rubric | LLM output matches a given rubric, using a Language Model to grade output |
| equals | output matches exactly |
| is-json | output is valid json (optional json schema validation) |
| perplexity | Perplexity is below a threshold |
| Similar | Embeddings and cosine similarity are above a threshold |
| answer-relevance | Ensure that LLM output is related to original query |
| context-faithfulness | Ensure that LLM output uses the context |
| context-recall | Ensure that ground truth appears in context |
| context-relevance | Ensure that context is relevant to original query |
| factuality | LLM output adheres to the given facts, using Factuality method from OpenAI eval |
| model-graded-close-qa | LLM output adheres to given criteria, using Closed QA method from OpenAI eval |
| select-best | Compare multiple outputs for a test case and pick the best one |
| contains | output contains substring |
| contains-all | output contains all list of substrings |
| contains-any | output contains any of the listed substrings |
| contain-json | output contains valid json (optional json schema validation) |
| icontains | output contains substring, case insensitive |
| icontains-all | output contains all list of substrings, case insensitive |
| icontains-any | output contains any of the listed substrings, case insensitive |
| javascript | provided Javascript function validates the output |
| levenshtein | Levenshtein distance is below a threshold |
| regex | output matches regex |
| other | Email [email protected] for additional metric support |
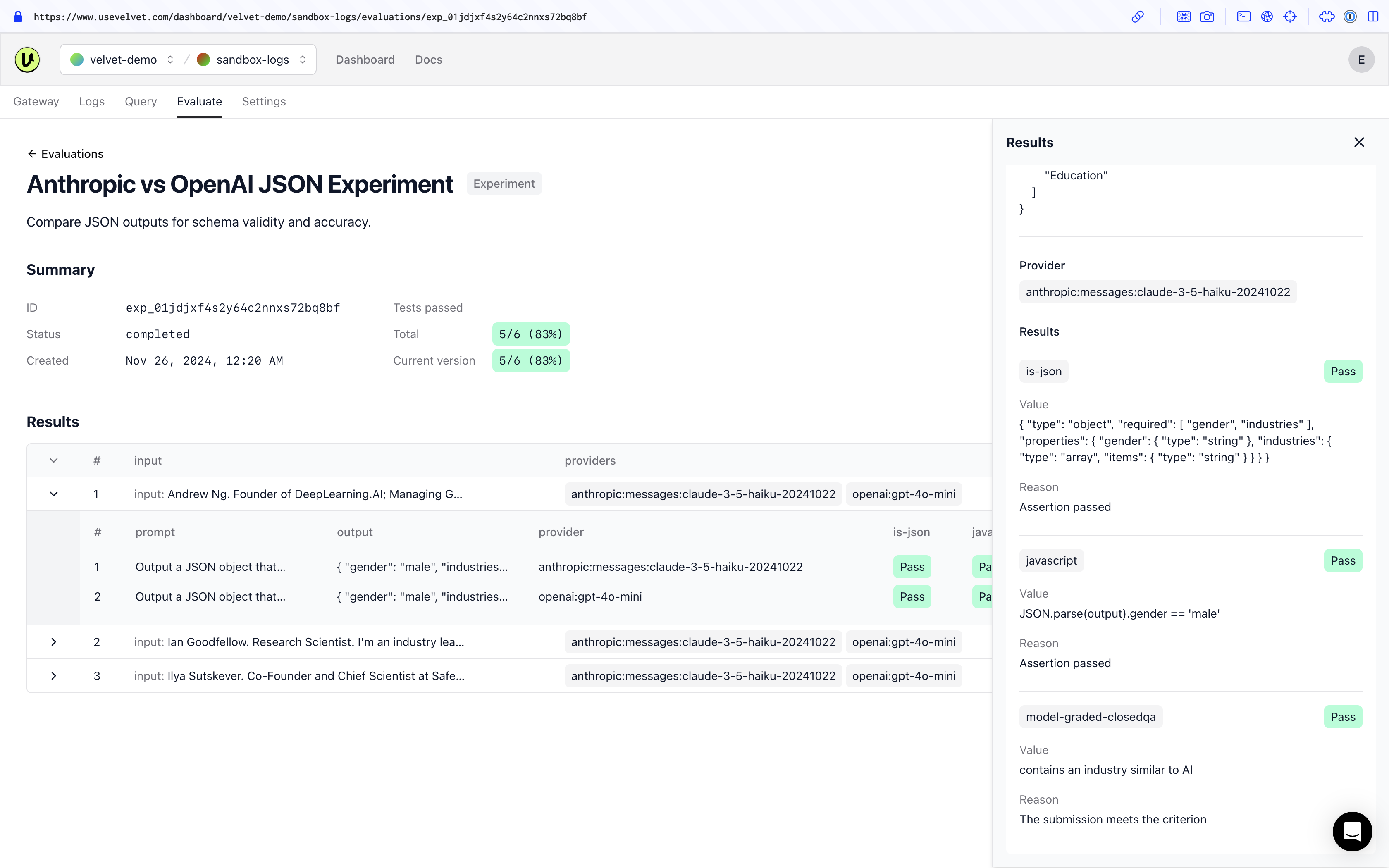
(2) Review experiment results
Navigate to the experiments tab once configured. Tap into the evaluation you want to review.
Experiments run once, and will have as many variants as you define. You'll get a weekly email summary.
Watch a video overview
Email [email protected] with any questions.
Updated 2 months ago