
Fly
Guide to connect Fly to Velvet
Connect your Fly database to your Velvet workspace. You can skip some steps if you've previously connected to other services.
1. Create a read-only user
Create a user with read-only permissions in Fly.
Connect to your Fly Postgres instance and run the following SQL statements via psql. These statements create a velvet_readonly user with the password a very good password and gives them the velvet_read_all_data role.
PostgreSQL v14 includes a pg_read_all_data role. Run fly image show in your Fly instance to determine your version.
Read-only user configuration:
-- Create a new user with read-only access to the database
-- Recommend to run each step one by one, as some steps may
-- fail if the user does not have the necessary privileges.
-- Step 1: Create the user
CREATE USER velvet_readonly WITH LOGIN PASSWORD 'your_secure_password';
-- Step 2: Grant connect privilege to the database
-- (replace your_database_name with the actual name - on supabase it's postgres)
GRANT CONNECT ON DATABASE postgres TO velvet_readonly;
-- Step 3: Grant usage on schemas. This allows the user to see the schemas
GRANT USAGE ON SCHEMA public TO velvet_readonly;
GRANT USAGE ON SCHEMA auth TO velvet_readonly; -- optional
-- Step 4: Grant select on all tables and views in the schemas
GRANT SELECT ON ALL TABLES IN SCHEMA public TO velvet_readonly;
GRANT SELECT ON ALL TABLES IN SCHEMA auth TO velvet_readonly;
-- Step 5: Ensure future tables and views in these schemas are also accessible
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO velvet_readonly;
ALTER DEFAULT PRIVILEGES IN SCHEMA auth GRANT SELECT ON TABLES TO velvet_readonly;
-- [OPTIONAL] Step 6: Bypass RLS policies
ALTER ROLE velvet_readonly BYPASSRLS;
Click Run and execute query.
2. Set static IPs
Configure network restrictions to allow Velvet's static IP addresses. Follow our static IP configuration guide.
3. Build your connection string
Read our general guide on URI construction here. The Fly-specific overview is below.
If you already have a connection string - copy it and skip to step #4.
Allocate a public IP address
Fly.io does not expose Postgres apps to the internet by default. In order to set up a connection to Fly.io you must expose the DB to the public internet by allocating a public IP address using the Fly CLI.
- Allocate an IPv4 address:
fly ips allocate-v4 --app <pg-app-name> - Pull down a
fly.tomlconfiguration file for your Postgres app:fly config save --app <pg-app-name>. Note: This could overwrite afly.tomlin the current directory. - Append the following to your fly.toml. This will allow connections on an external port, and direct incoming requests to your Postgres instance.
[[services]]
internal_port = 5432 # Postgres instance
protocol = "tcp"
[[services.ports]]
handlers = ["pg_tls"]
port = 5432
Deploy with the new configuration.
- Figure out which image and tag (Postgres version) you’re on:
fly image show --app <pg-app-name> - Deploy your cluster, using
--imagewith theimage:tagfound in the previous step:fly deploy . --app <pg-app-name> --image flyio/postgres:<major-version>
Copy the connection URI
Read our general guide on URI construction here. The Fly-specific overview is below.
- The connection URI is in the form:
postgres://{username}:{password}@{hostname}:{port} - The
hostnameis internal, so you must substitute your newly publicly reachable hostname (<pg-app-name>.fly.dev) - Provide a read-only user in the username/password.
- Copy the connection URI.
4. Connect your database
Connect your database to Velvet using your connection string.
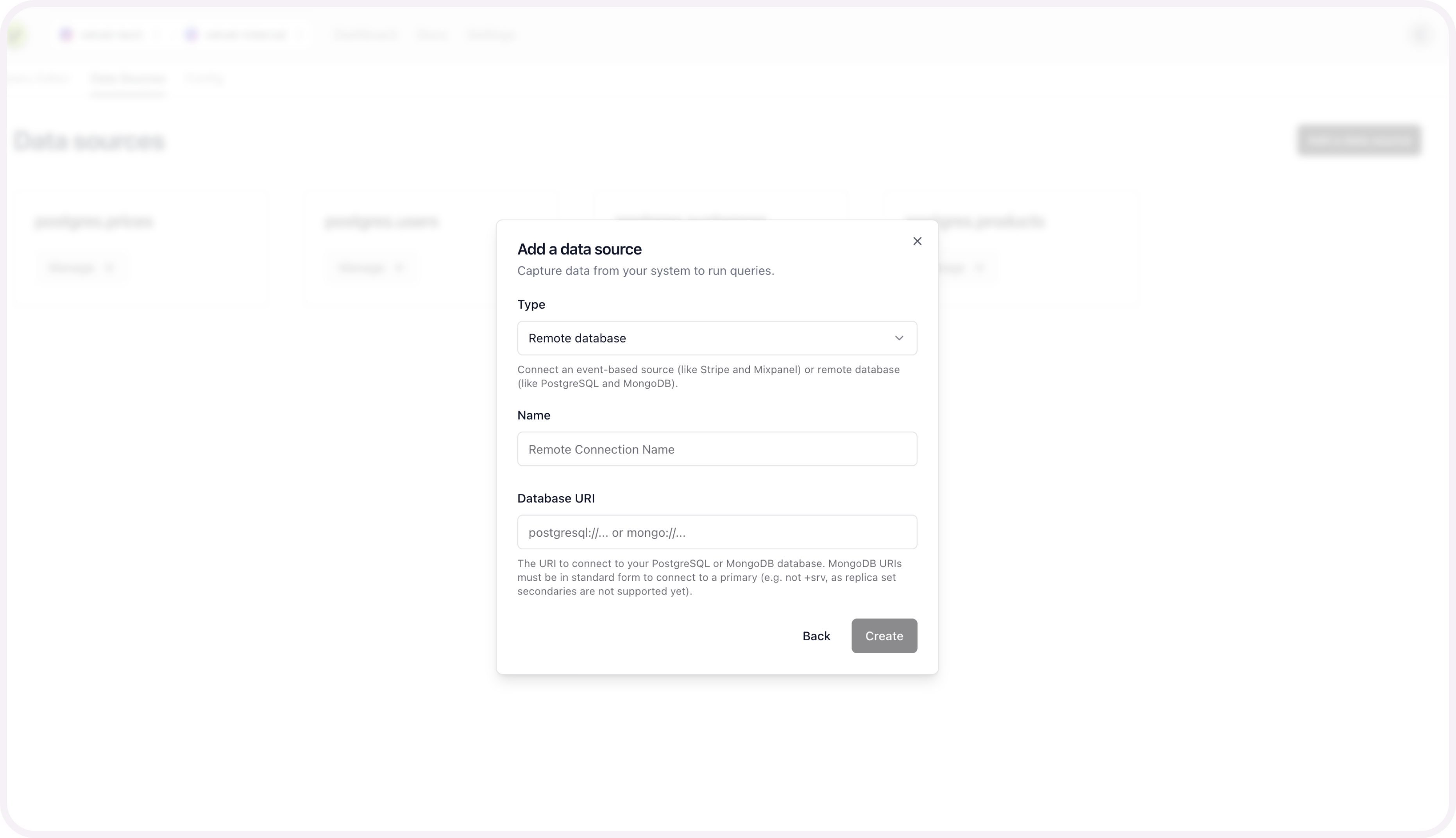
- Tap into a workspace in your Velvet dashboard
- Tap "Add a data source"
- Select type "Remote database"
- Name your database
- Paste in your database URI
- Press create
If you run into any errors, schedule a call or email [email protected].
Once your database is connected, you're ready to use the AI SQL editor. Close out of the modal to start using the editor on top of your database.
Schema mapping is optional, and only required if you want to query multiple sources at the same time.
5. [optional] Schema mapping for unified sources
This configuration is only required to query multiple data sources at the same time. For example - two databases at the same time, or stripe webhooks alongside your database tables.
You can set up this unified mapping any time.
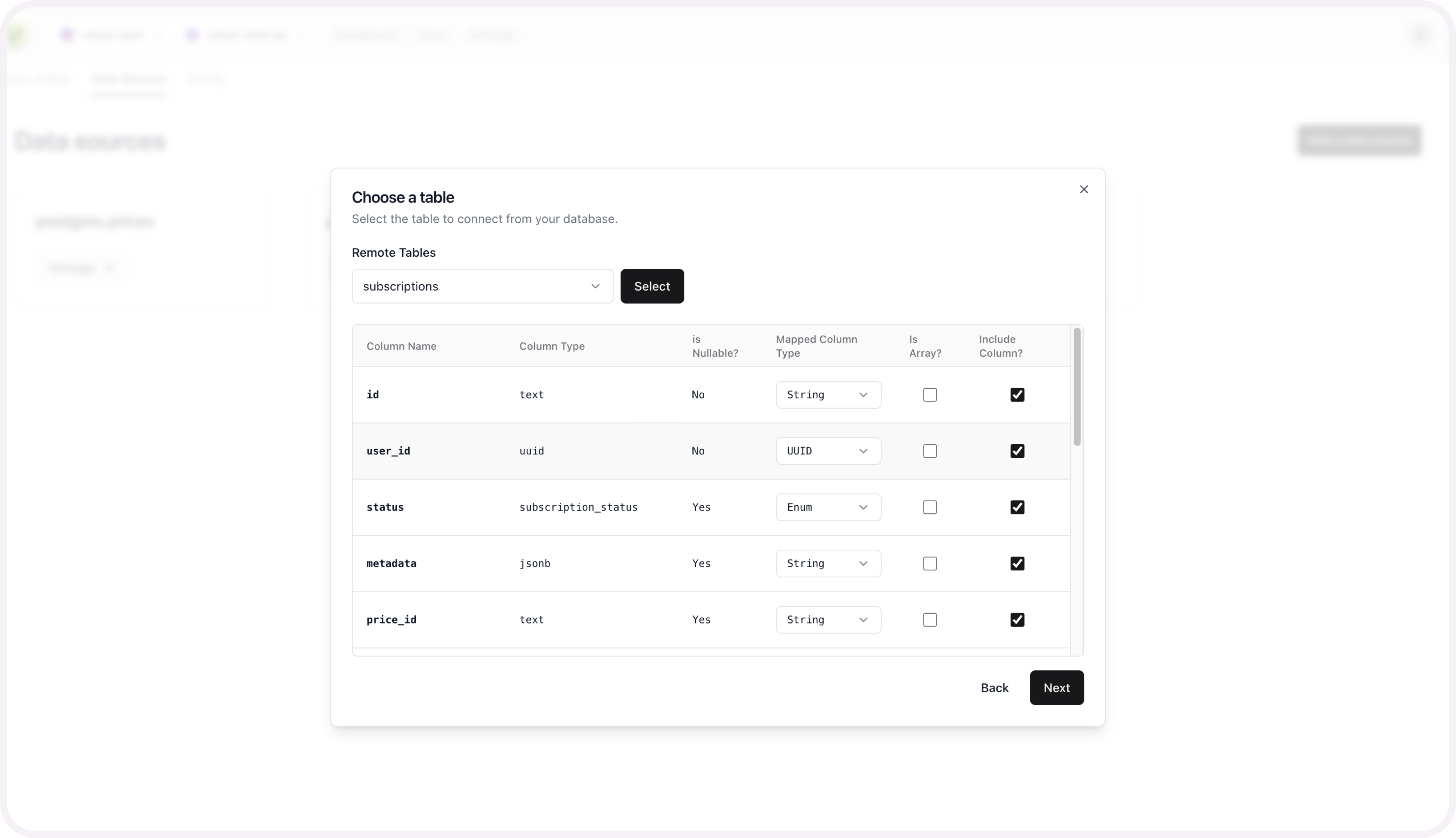
Add schema mapping context
After you connect your database, you'll be prompted to configure the schema for each table you set up.
Name your table to create this source.
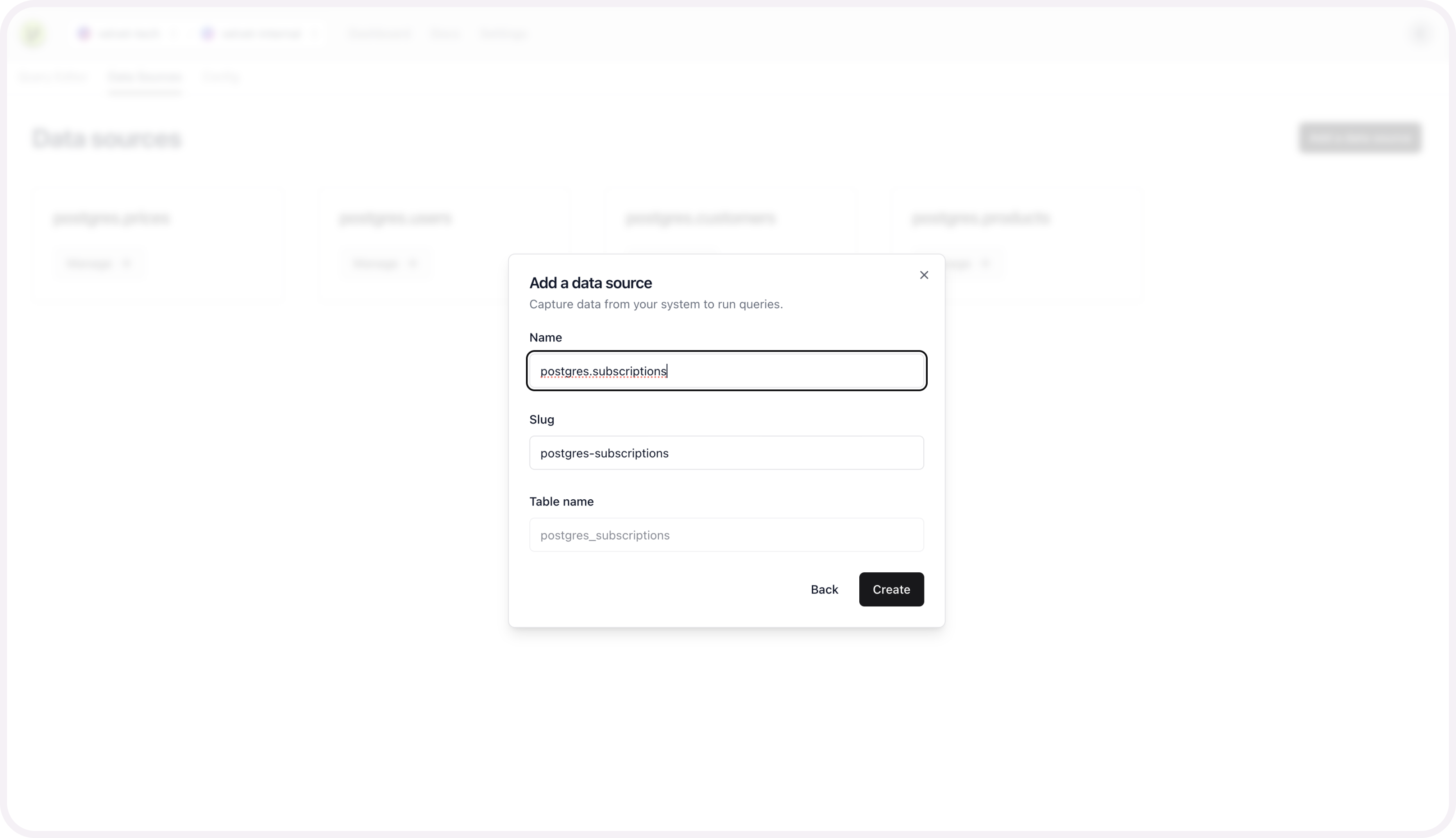
Repeat these schema mapping steps for each table you want included as a unified data source.
Get help
Email [email protected] if you need additional support.
Updated 3 months ago